The main goal of the ELSNET project being an annotation at the semantic level of description displaying the various types of subcategorization frames the question arose whether to include sentential complements in the analysis. On the one hand, these complements are an important part of the subcategorization properties of the verb and, therefore, could be telling with respect to the syntactic as well as semantic selection of the verb. On the other hand, they are difficult to annotate and to group under semantic sorts. For Italian the same problem had come up and it was decided to include only very few examples of sentential complements in order not to avoid them completely and to be able to display some typical meanings of verbs that can only be expressed by sentential complements. For German it was decided to exclude sentential complements altogether with respect to the annotation. However, they were kept in mind and were listed in the appendix wherever they can possibly alternate with nominal or prepositional complements in order not to lose completely the information they can give to this respect.
List of subcategorization frames:
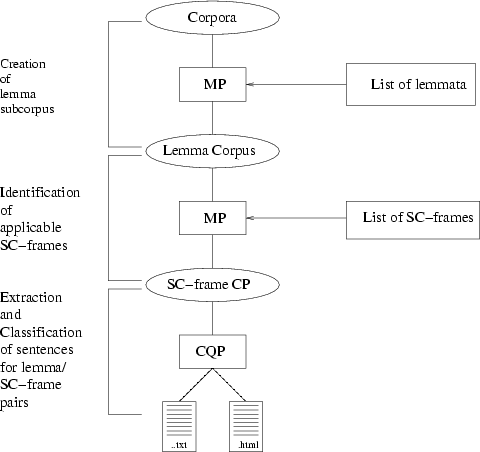
A first step in extracting data from corpora was to create a subcorpus of all sentences containing the lemmata of the selected verbs. (Thereby, sentence referres not to the whole sentence but only to the clausal part containing the respectiv verb.) The applicable SC-frames were identified along with the respective templates. By means of these templates sentences were extracted out of the lemma corpus and stored as different subcorpora, one for each template.
In a seperate step groupings for each template were made displaying
the frequency of this template for each lemmata. These groupings were
then aligned with the respective SC-frames and manually filtered.
Each lemma SC-frame pair was then separately applied to the respective
subcorpus using CQP commands to extract the relevant sentences. These
sentences were then stored in txt and html lemma files, which display
the sentences sorted according to their SC-frames.
Concentrating on the diversity of verb-noun-collocations an additional method was used to extract data from corpora. Assuming that the relevant complements are to the right of a sentence preceding the main verb, verbs were extracted along with the next noun to the left, where appropriate also with the respective preposition. These verb-noun-pairs were then listed and manually checked for interesting and applicable collocations. The respective sentences were extracted out of the corpus.